

Saving Download Bandwidth with RAUC Adaptive Updates
With version 1.7, the RAUC update framework was equipped with built-in HTTP(S) streaming support. While this avoided the need for additional storage on the target to serve as temporary bundle storage, it still required to download the entire update bundle.
But, especially when network throughput is a bottleneck or traffic is quite expensive, the need to save download bandwidth comes up and the common answer to this is delta updates.
A conventional delta update is generated by creating the binary or file-based difference between the current version and the intended version. While this allows the update to be as small as possible, it adds some significant conceptional complexity to the update:
- one need to know which source versions you have in the field
- one needs to deploy the matching updates
- an update to an arbitrary version works only by sequentially applying the delta updates for all intermediate versions.
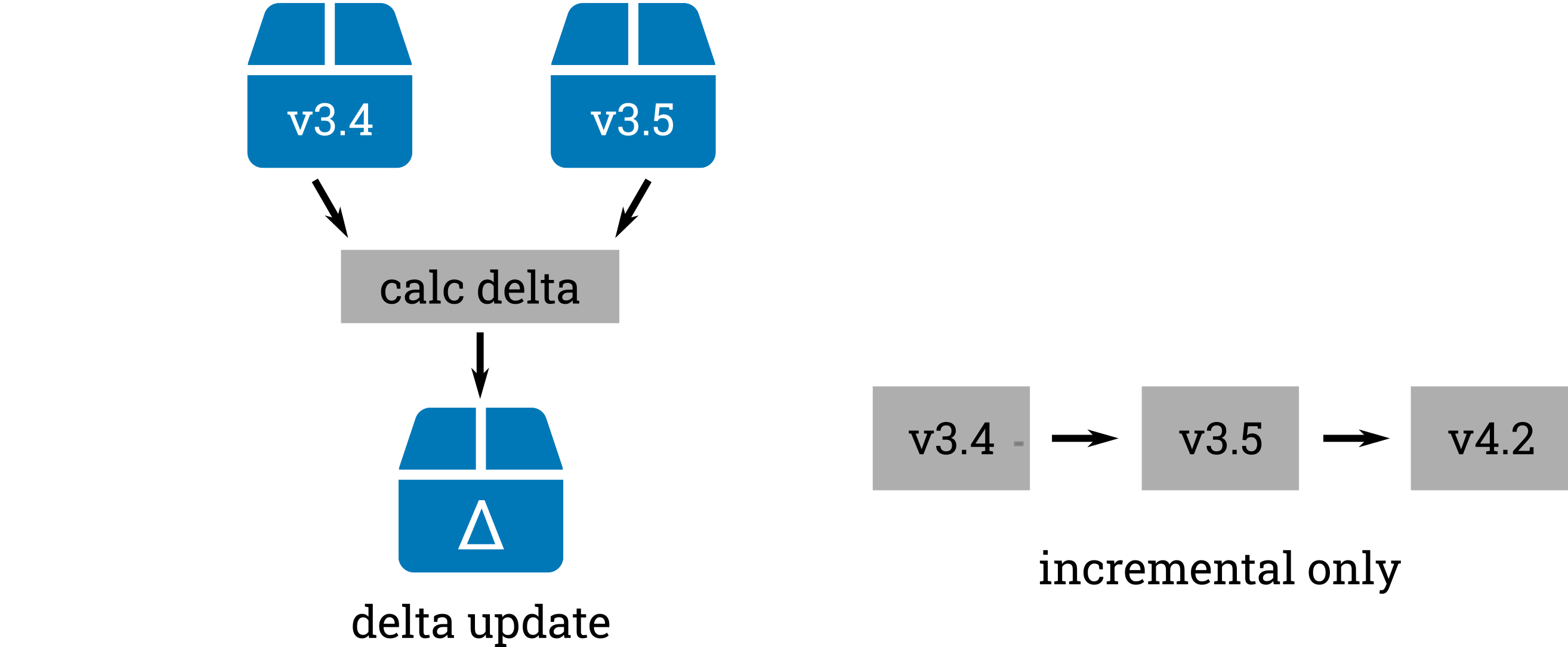
Conventional delta updates only allow updating from one specific version to another specific version
Yes, one can partly address this problem by adding more complexity to the server logic and provide or generate the required delta on-demand, but this significantly limits the possible use-cases and requires storing data for the all previous versions.
Thus, for RAUC, we have decided to follow another (high-level) approach for optimizing the download bandwidth: We have called it adaptive updates.
If you cannot immediately picture what it's all about, don't hesitate and read on. It took us a second try to find the right name [1].
Adaptive Updates
Adaptive updates are a general concept to save download bandwidth in RAUC. In version 1.8, one adaptive mode is implemented in RAUC, called block-hash-index that we will discuss in more detail in the next sections.

With adaptive updates one can update from any version
The basic idea of adaptive updates is to place additional (meta-)data in the bundle that allows the RAUC service to optimize the download while always allowing updates from any version.
As a reminder: Since we have streaming capabilities in RAUC allowing verified random access to the remote bundle, additional files in the bundle only need to be downloaded when they are used.
The update bundle's manifest describes which adaptive method(s) are enabled for each slot image individually using the adaptive key (as a semicolon-separated list):
[update]
compatible=Test System
...
[image.rootfs]
filename=rootfs.ext4
adaptive=block-hash-index;rsync-delta-checksum;...
To be fully backwards compatible and to easily allow adding new adaptive methods, RAUC simply ignores all unknown adaptive methods. Thus, in the 'worst' case, RAUC just streams the full image into the target slot, but it will never reject it. If RAUC knows one or multiple methods, it will select one as appropriate.
Since most adaptive methods make (or will make) use of the newly introduced RAUC data directory for storing information, one should also make sure to have this configured in the target's system.conf:
[system]
compatible=Test System
...
data-directory=/data
Adaptive Update Method block-hash-index
The block-hash-index adaptive method can be used for file system images, mainly for file systems such as ext4 that align the data to 4K (or larger) blocks. It is the first method implemented in RAUC and part of the v1.8 release.
The method leverages RAUC streaming capabilities that provide random access to remote update bundles via HTTP range requests to download only necessary parts of the bundle.
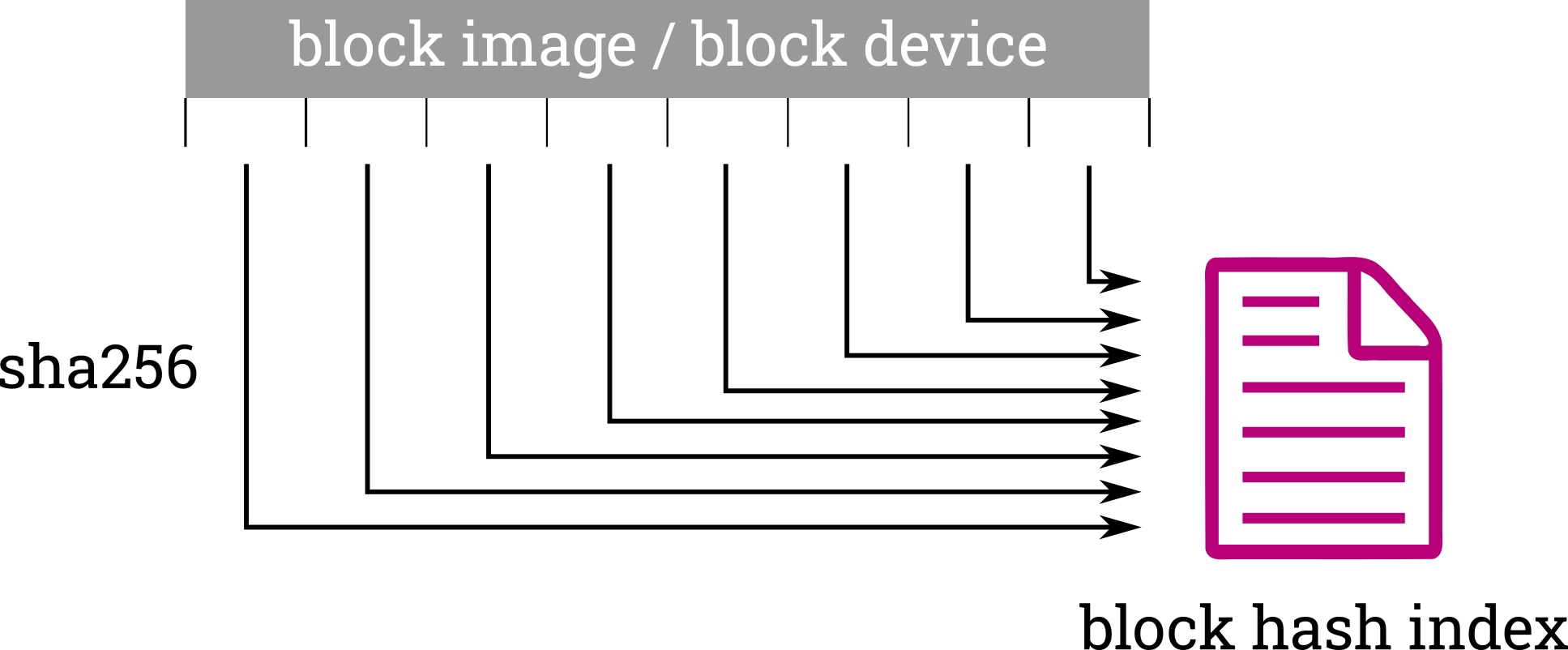
block-hash-index: Creation
If block-hash-index is set as a method for an image in the manifest, RAUC generates a hash index file during bundle creation. This works by splitting the image into 4K-sized chunks and calculating the SHA-256 hash for each. The resulting list of chunk hashes unambiguously describes the source data and is what we will refer to as the block hash index. The block hash index file is placed next to the original image inside the bundle at a well-known location.
They key concept for reducing the actual data to download is to find matching data chunks on the device's local storage and use these in instead of downloading the remote ones. In an A/B update scheme, the best chance for finding identical chunks is to search in the active and inactive slots.
Thus, when RAUC installs an image from the bundle that has the block-hash-index adaptive mode enabled, RAUC first downloads only the (much smaller, <1%) block hash index file.
RAUC then performs the same chunking and hashing operation (as described above) on both the (inactive) target slot as well as its corresponding currently active slot and generates a block hash index for each.
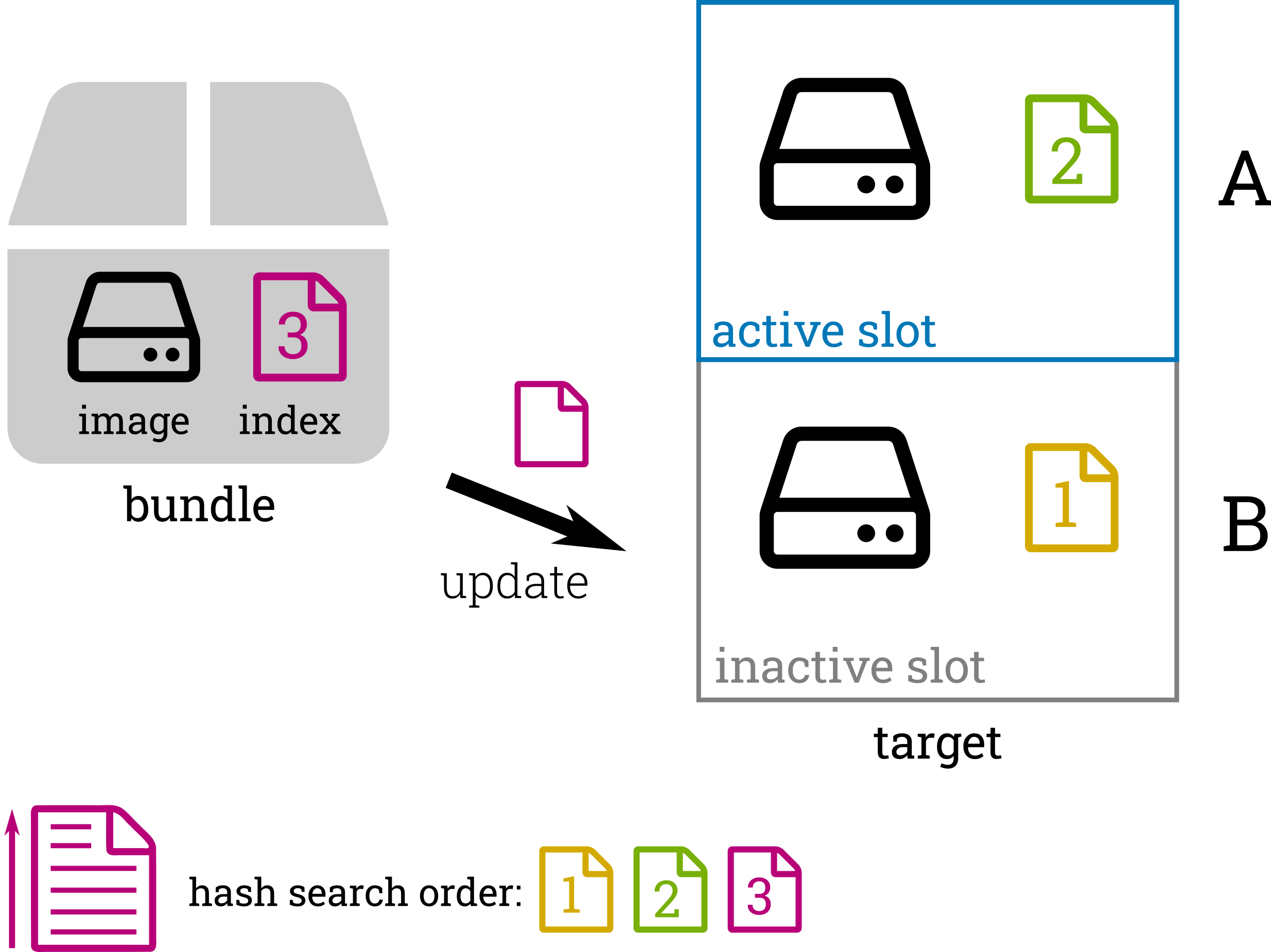
block-hash-index: Installation
To write the new image to the target slot, RAUC iterates through the image's block hash index. For each hash, RAUC checks if this hash (and thus the required chunk data) can be found in any block hash index. If a hash is found, RAUC copies the corresponding data chunk from the block device/image described by the hash index.
RAUC searches through the hash indexes in the following order:
- the active slot
- the inactive (update) slot
- the update image in the bundle
This ensures that local chunks are searched and used first and only those chunks that are not available locally have to be downloaded.
Built-in Optimization
Since the on-demand generation of block hash indexes for the slots will (depending on CPU and IO performance) add some time to the installation, they are cached in the RAUC data directory. Only if there is no cache or the cached information does not match the actual data, the hash index will be re-generated from the block device.
Especially since images often do not fill the entire space in a slot, one of the very frequently used hashes will be those for the zero-chunk. RAUC has a zero chunk in memory that it will use before any lookup mechanism takes place.
Outlook: Future Adaptive Methods
While block-hash-index is the initial adaptive method implemented and is part the RAUC 1.8 release, there are plans for additional methods.
Adaptive Update Method tree-rsync-checksum
While the previously introduced adaptive method is applicable to block images only, the underlying approach can be used for directory-tree-based updates (as RAUC already supports in the form of tar archives), too.
Instead of generating a hash index for a block device on a chunk basis, for directory trees one can simply generate a hash index by calculating and storing one hash for each file. By doing this for the directory tree that comes with the update 'images' as well as for the directory trees of the currently active and inactive slots one again has a set of three hash index files.
When installing the update, we can again download the hash list describing the update directory tree and iterate over it while searching for a file with the same hash in the local slots first. Only files whose hash RAUC cannot find locally have to be downloaded from the remote bundle.
With rsync, there is already a tool available that can handle the checksum-based synchronization of files with using multiple sources as reference.
The only missing piece of the puzzle is the ability to store/cache the checksums so that they do not have to be re-calculated on each update.
There are two possible solutions for this out in the field as patches:
saving and storing checksums in .rsyncsums files:
saving and storing checksums in xattrs:
The actual copying will the be as similar as running
rsync --delete --copy-dest=<active-slot> <bundle>/rootfs.tree <inactive-slot>
Adaptive Update Method delta-image
Remember? In the beginning of this post we've argued against the use of conventional delta updates. Now, having adaptive updates introduced, we can rehabilitate them a bit.
The idea behind the adaptive method delta-image is quite simple: We create conventional delta images between old bundle versions and a new bundle version using some binary diff tool.
But, instead of using only one delta image, we can add several as additional artifacts to the bundle so that we gain benefit from both: If there is an optimized delta artifact matching a currently available bundle version, use it. If there is none, just perform a normal image update.
| [1] | Trivia: The working title of 'adaptive updates' was 'incremental updates' |
Getting Started With block-hash-index Adaptive Method
If this brief excursion has piqued your interest and you intend to evaluate adaptive updates for your project, here is a summary of things to do to enable adaptive updates:
Ensure you are using block device images
It is highly recommended to use a 4k-aligned file system like ext4, erofs or squashfs
Ensure you build verity bundles (see docs)
Ensure you have HTTP streaming support working (see docs)
Configure a data-directory in your system.conf (see docs)
Enable adaptive=block-hash-index in your bundle manifest
Build and install a bundle (over HTTP)
Note
You also need to ensure that both the target block device size as well as the size of your image are a multiple of 4kiB.
Important
The block-hash-index method does not work with NAND / UBIFS yet.
If an adaption for NAND is required, feel free to contact us or to discuss and contribute via GitHub.
Tip
For testing without actual hardware, the meta-rauc-qemux86 layer from the meta-rauc-community project is a good starting point.
I have prepared PR #37 as a jump-start for trying out adaptive updates.
See this post for an introduction to using the RAUC-enabled QEMU image built by meta-rauc-community.
Measuring & Debugging
To check if adaptive updates are working, you should inspect the rauc service log, e.g. with:
journalctl -u rauc
when using systemd.
Look for lines noting 'hash index', like this one:
using existing hash index for target_slot from /data/slot.rootfs.1/hash-d60b4e16226f704249fc6bf4d99c9aae0be41706ac7dcee0e4aa1d53792c9577/block-hash-index hash index (35223 chunks) does not cover complete data range (38400 chunks), ignoring the rest building new hash index for active_slot with 38400 chunks using existing hash index for source_image from /mnt/rauc/bundle/core-image-minimal-qemux86-64.ext4.block-hash-index
To see if adaptive updates are working and for evaluating how it performs on your system, you should have a look at the access stats that are printed:
access stats for zero chunk: count=8235 sum=8235.000 min=1.000 max=1.000 avg=1.000 recent-avg=1.000 access stats for target_slot_written (reusing source_image): count=25567 sum=204.000 min=0.000 max=1.000 avg=0.008 recent-avg=0.000 access stats for target_slot: count=25363 sum=1.000 min=0.000 max=1.000 avg=0.000 recent-avg=0.000 access stats for active_slot: count=25362 sum=25304.000 min=0.000 max=1.000 avg=0.998 recent-avg=0.969 access stats for source_image: count=58 sum=58.000 min=1.000 max=1.000 avg=1.000 recent-avg=1.000
You can ignore the min, max, avg, and recent-avg values since they are only emitted by the generic RAUC stats framework.
You see the four internally used block hash indexes being printed in the order they are accessed by RAUC as well as an additional zero chunk entry that represents the built-in access to the zero chunk hash optimization noted above.
The count refers to the number of times the corresponding index was accessed while the sum is the number of found chunks in this index.
Tip
The lower the count or sum for source_image is, the more chunks RAUC was able to find locally and the less it has to download.
In the example above 58 chunks were downloaded from the bundle, while 25304 were used from the active slot and 204+1 chunks were (re)used from the target slot.
Note
In addition to checking the stats for chunks, you should also check the download stats printed by RAUC, especially the dl_size.
Optimization Approaches
If, even for small rootfs changes, the resulting difference, i.e. the number of fetched chunks is quite high, these are some things one should have a look at:
Ensure using a build system that has reproducible builds enabled.
When using ext4, ensure your block size is 4096. You can check this with:
dumpe2fs rootfs.ext4 | grep "Block size"
To enforce block size for mkfs.ext4, add -b 4096 argument.
Even if file system contents are (nearly) identical, the generated images may have significant differences. Have a look at https://reproducible-builds.org/docs/system-images/ for possible solutions to this.
The bundle image chunks are accessed through the bundle SquashFS, thus with a large SquashFS block size, some unnecessary data may have to be downloaded, as each compressed SquashFS block needs to be downloaded completely.
You can e.g. reduce the block size to 32kiB by adding --mksquashfs-args="-b 32k" to the rauc bundle call.
Further Readings
RAUC v1.8 Released
When September ends and summer is over, it's a good opportunity to take advantage of the shorter days and comfortably update to the latest RAUC version we have just released into the wild: v1.8

You can buy RAUC and labgrid sponsor packages now
RAUC and labgrid are open source software projects started at Pengutronix, that are quite successful in their respective niche. Starting today you can buy sponsorship packages for both projects in the Linux Automation GmbH web shop, to support their maintenance and development.RAUC v1.15 Released
It’s been over half a year since the RAUC v1.14 release, and in that time a number of minor and major improvements have piled up. The most notable change in v1.15 is the newly added support for explicit image types, making handling of image filename extensions way more flexible. Other highlights include improved support for A/B/C updates and several smaller quality improvements. This release also includes the final preparations for upcoming features such as multiple signer support and built-in polling.
RAUC - 10 Years of Updating 🎂
10 years ago, almost a decade before the Cyber-Resilliance-Act (CRA) enforced updates as a strict requirement for most embedded systems, Pengutronix started RAUC as a versatile platform for embedded Linux Over-The-Air (and Not-So-Over-The-Air) updates.